

Pandasを使ってデータ分析をしている。
Seriesのreplaceメソッドを使うと結果がNaNになるケースがある。
原因を教えて欲しい。
こんなお悩みを解決します。
データ分析時に、特定のパターンに合致するデータに対し、処理を行いたいときがあります。
その時の前処理としてpandas.Seriesのreplaceメソッドを使うことが多いのですが、使い方を誤り、ハマった経験があるので、解決策とあわせて紹介します。
簡単な事例も用いて紹介するので、興味がある方はぜひ最後までご覧ください。
問題の挙動
以下のように、数値、文字列が混ざったSeries型のデータを想定します。
import pandas as pd
data = ['0', 1, 2, '3', '4None', 5.0]
series = pd.Series(data)
この時、データに文字列が含まれているため、Seriesのデータ型はobject型になります。

データ分析時には数値のみの方が都合が良いため、以下のように置換処理を行ったとします。
series.str.replace('\D+', '', regex=True)これですべて数値に変換されることを期待しますが、期待した通りにはならず、以下のような結果となってしまいます。
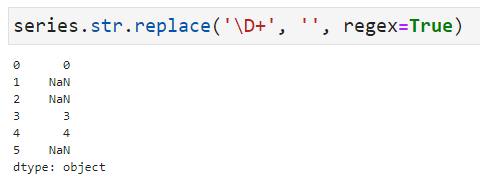
以降で、このような結果になる問題とその解決方法について解説します。
問題の発生原因
問題の発生原因は、数値に対してstr.replaceの処理が行えない、という点が挙げられます。
内部の具体的な処理までは追っていませんが、数値に対して置換処理(replace処理)を適用しようとするため、結果がNoneになり、Pandas上でNaNとして扱われると考えられます。
それぞれのデータに対する処理結果をまとめると以下のようになります。
| データ | データ型 | str.replaceの適用可否 | 出力結果 |
|---|---|---|---|
| '0' | str | 適用可能 | '0' |
| 1 | int | 適用不可能 | NaN |
| 2 | int | 適用不可能 | NaN |
| '3' | str | 適用可能 | '3' |
| '4None' | str | 適用可能 | '4' |
| 5.0 | float | 適用不可能 | NaN |
解決方法
解決策としては、以下の2つの方法があります。
- 一度str型に変換してから処理する。
- str.replaceではなく、replaceを直接呼び出す。
ここでは、実装がシンプルな2.の方法を紹介します。
コードを書き換えて実行した際の結果は、以下のようになりました。
- series.str.replace('\D+', '', regex=True)
+ series.replace('\D+', '', regex=True)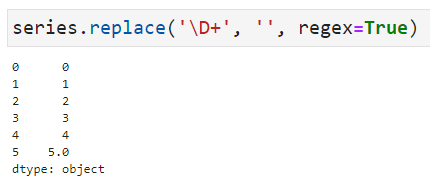
期待通りの変換が行えていることが分かります。
1点、注意点として、データがobject型になっていることから、上記の出力結果は、数値と文字列が混在した状態となります。
このため、すべて数値として扱うためには、以下のようなキャストの処理が必要になります。
series.replace('\D+', '', regex=True).map(int)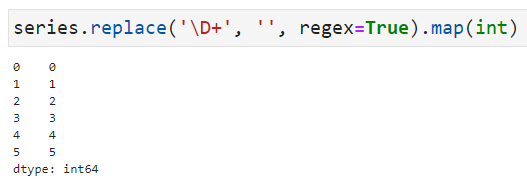
まとめ
今回は、pandas.Seriesのreplaceメソッドの意図しない挙動を取り上げ、その解決方法について解説しました。
機械学習やデータ分析を行う際は、データ加工の処理は必須になるため、想定外の処理が行われていないかを逐一確認する必要があります。
今回のケースは、想定外の処理が行われる一例となるため、同様のことで悩んでいる方のお役に立てれば幸いです。
効率良く技術習得したい方へ
今回の話の中で、プログラミングについてよく分からなかった方もいると思います。
このような場合、エラーが発生した際に対応できなくなってしまうため、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。
-

-
【比較】プログラミングスクールおすすめランキング6選【初心者向け】
続きを見る