

人手で競馬予想を行うのは限界があるため、機械学習を利用したい。
生成した特徴量を用いて機械学習モデルを構築する方法とモデルの評価方法を教えて欲しい。
こんなお悩みを解決します。
今回は、古典的な機械学習手法を用いたモデルの構築方法と構築したモデルの評価方法について解説します。
実際にPythonの実装結果もあわせて記載していくので、興味がある方はぜひご覧ください。
効率良く技術習得したい方へ
短期間でプログラミング技術を習得したい場合は、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。

参考サイト
学習モデルを定義するにあたり、以下のサイトを参考にしました。
https://qiita.com/dijzpeb/items/db74aa9726aaf55201eb
モデルの学習方針・評価方針
生成した特徴量の良し悪しも確認したいため、今回は以下のような方針でモデルを学習・評価します。
| 項目 | 内容 |
|---|---|
| 機械学習手法で解く問題 | 1着~3着の馬を予想する。 |
| 制約条件(学習時・評価時) | 上位6着の馬のみの情報をもとに学習・評価する。 ※7着以降の馬の情報は参照しないようにしています。 |
| 利用する機械学習手法 | lightGBMによる2値分類を行う。 |
| 学習方法 | GBDT(勾配ブースティング決定木)により、モデルパラメータを最適化する。 |
| 学習用データ、評価用データ | ・学習用データ:2880レース分 ・評価用データ:1272レース分(検証用データ:637レース分、テスト用データ:635レース分) |
モデル構築の概要
今回は、Microsoft社が開発・運用しているlightGBMとoptunaと呼ばれるハイパーパラメータ探索用のライブラリを利用します。
このため、機械学習手法を利用するためのラッパーが、自前で実装する部分となります。
また、利用する機械学習手法が変更になる(例えば、lightGBMからニューラルネットワークに変更する)場合を考慮し、モデル生成の実装にデザインパターン「Factory Method(ファクトリーメソッド)」と「Template Method(テンプレートメソッド)」を組み合わせて構築しました。
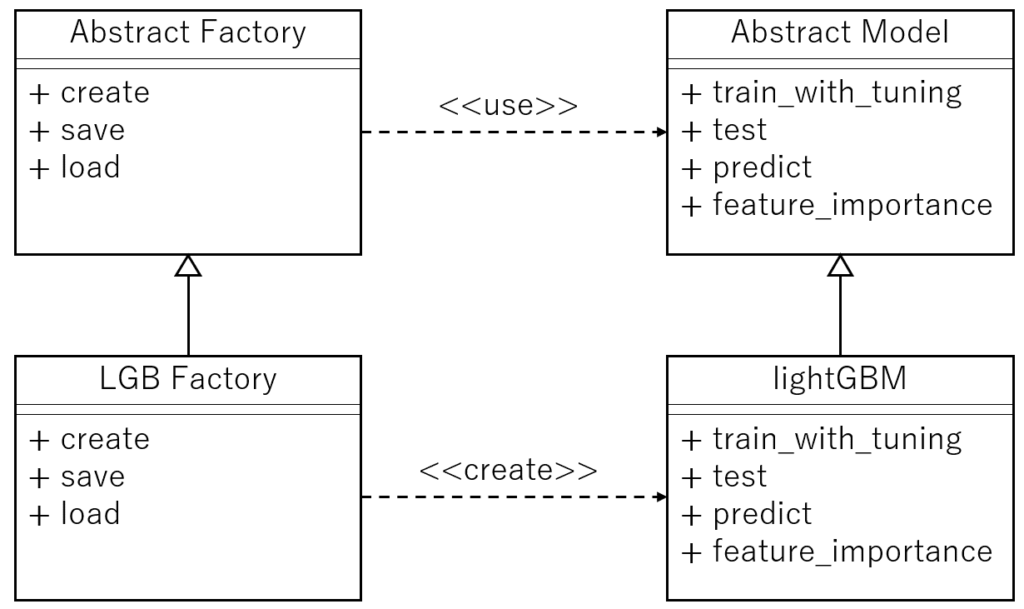
複数のモデルを利用したい場合は、具象クラスであるLGB FactoryとlightGBMに該当するクラスをモデルごとに作成しておけば、Factoryクラスのインスタンスを切り替えるだけで、モデルごとの評価が行えるようになります。
また、今回はモデルとデータセットを一括で管理したいため、Template methodをベースとしたクラス間の関係図は以下のようになります。
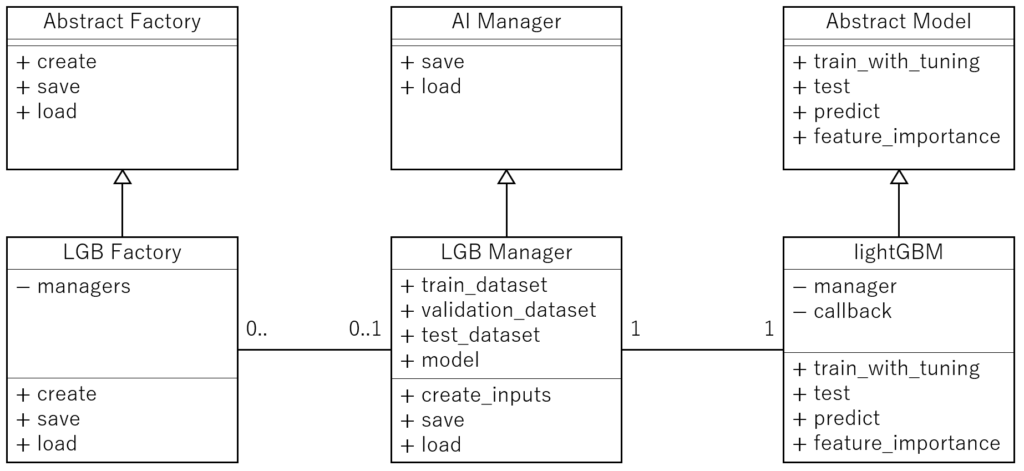
それぞれのクラスの内訳・機能/役割は、以下のようになります。
| 区分 | クラス名 | メソッド | 機能/役割 |
|---|---|---|---|
| 抽象クラス・抽象メソッド | Abstract Factory | - | オブジェクト生成用の抽象クラス |
| create | オブジェクトを生成する役割を持つ抽象メソッド | ||
| save | オブジェクトを保存するための抽象メソッド | ||
| load | 保存したオブジェクトを読み込むための抽象メソッド | ||
| Abstract Model | - | 機械学習手法を用いて、学習・推論・評価を行うための抽象クラス | |
| train_with_tuning | ハイパーパラメータのチューニングも行いつつ、学習する役割を持つ抽象メソッド | ||
| test | 学習済みモデルで評価を行う役割を持つ抽象メソッド | ||
| predict | 与えられたデータに対し、推論を行う役割を持つ抽象メソッド | ||
| feature_importance | 特徴量の重要度を計算する役割を持つ抽象メソッド | ||
| 具象クラス・具象メソッド | LGB Factory | - | lightGBMを対象としたオブジェクト生成用の具象クラス |
| create | lightGBM用のインスタンスを作成するための具象メソッド | ||
| save | モデルとデータセットを一括で保存するための具象メソッド | ||
| load | モデルとデータセットを一括で読み込むための具象メソッド | ||
| lightGBM | - | lightGBMによる学習・推論・評価を行う具象クラス | |
| train_with_tuning | lightGBMのハイパーパラメータのチューニングも行いつつ、学習するための具象メソッド | ||
| test | 学習済みのlightGBMモデルで評価するための具象メソッド | ||
| predict | 与えられたデータに対し、学習済みのlightGBMで推論を行うための具象メソッド | ||
| feature_importance | lightGBMにおける特徴量の重要度を計算するための具象メソッド | ||
| データクラス | AI Manager | - | モデルとデータセットを管理するためのデータクラス |
| save | 与えられたデータを保存するためのメソッド。 保存形式や保存時のディレクトリ構成は、このメソッドで定義する。 |
||
| load | 保存したデータを読み込むためのメソッド。 saveメソッドの構成に合わせて定義する。 |
||
| LGB Manager | - | lightGBM用のデータクラス。以下のメンバを管理する。 ・train_dataset ・validation_dataset ・test_dataset ・model |
|
| save | 自身のオブジェクトを保存する際の処理を記載する。 今回は、継承先の保存形式(pickle形式)に合わせてデータを加工している。 |
||
| load | 読み込んだデータから自身のオブジェクトを生成する。 | ||
| create_inputs | 生データから自身のオブジェクトを生成するためのデータを作成する。 lightGBMで利用するデータセットの形式に合わせてデータを加工する。 |
ディレクトリ構成
以降では、Pythonを用いて前処理を行うためのプログラムについて解説します。
該当するプログラムを追加した後のディレクトリ構造は、以下のようになります。
./
|-- Dockerfile
|-- docker-compose.yml
|-- entrypoint.sh
`-- workspace/
`-- keiba/
|-- data/
| |-- html/
| | |-- horse/
| | |-- ped/
| | `-- race/
| |-- master/
| `-- raw/
| |-- results.pkl
| |-- race_info.pkl
| |-- payback.pkl
| |-- horse_results.pkl
| `-- ped_results.pkl
|-- models/
|-- modules/
| |-- __init__.py # [変更]モジュールロード用
| |-- Constants.py
| |-- Collection.py
| |-- Preprocess.py
| |-- DataManager.py
| |-- FeatureEngineering.py
| `-- Learning.py # [追加]学習・評価用
|-- scrape.ipynb
`-- preprocess_learning.ipynb # [変更]学習・評価用の処理を追加
以降では、処理の全体の流れを解説後、実装例と共に処理内容を解説したいと思います。
処理全体の流れ
処理全体の流れとしては、以下のようなステップとなります。
- 前処理終了後、上記で説明したLGB Factoryクラスのインスタンス(factory)を作成する。
- factoryからcreateメソッドを呼び出し、lightGBMによる学習・評価用のインスタンス(lgb)を作成する。
- lgbからtrain_with_tuningメソッドとtestメソッドをこの順で呼び出し、学習・評価を行う。
- 学習済みモデルから特徴量の重要度を取得する。
これを実装した結果は、以下のようになります。
%load_ext autoreload
%reload_ext autoreload
%autoreload 2
import pandas as pd
from modules import Preprocess, LGBFactory
from UserParams import Params
from datetime import datetime
# 最大列の表示数を指定
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 30)
# ==================
# 前処理&データ結合
# ==================
# 省略
# ==================
# 学習・評価
# ==================
# インスタンス作成
factory = LGBFactory()
lgb = factory.create(inputs.features)
# データ構成の確認(Jupyter用)
#_lgb_manager = lgb.__dict__['_LightGBM__manager']
#_train_size = len(_lgb_manager.train_dataset.data)
#_valid_size = len(_lgb_manager.validation_dataset.data)
#_test_size = len(_lgb_manager.test_dataset.data)
#print(f'train size: {_train_size} (≒ {int(_train_size / 6)}レース分)')
#print(f'validation size: {_valid_size} (≒ {int(_valid_size / 6)}レース分)')
#print(f'test size: {_test_size} (≒ {int(_test_size / 6)}レース分)')
# ハイパーパラメータ探索付きの学習実施
best_params = lgb.train_with_tuning()
# 最適なハイパーパラメータの確認(Jupyter用)
#best_params
# 評価実施
lgb.test()
# 特徴量の重要度確認 (Jupyter用)
#importance = lgb.feature_importance()
#importance.head(30)
# モデルの保存
_ = factory.save(lgb, version=f'model-{_year}-2022')また、Learning.pyで定義しているそれぞれのクラスの実装内容は、以下のようになります。
抽象クラス・抽象メソッド
_AbstractFactory
こちらは、オブジェクト生成用の抽象クラスとなります。
# モデル生成を行う抽象クラス
class _AbstractFactory(metaclass=ABCMeta):
@abstractmethod
def create(self, df, test_size, valid_size):
# 具象クラスで定義したインスタンスを生成するためのメソッド
pass
@abstractmethod
def save(self, manager, version):
# 生成したインスタンスを保存するためのメソッド
pass
@abstractmethod
def load(self, filepath):
# 保存したインスタンスを読み込むためのメソッド
pass_AbstractModel
こちらは、機械学習手法を用いて、学習・推論・評価を行うための抽象クラスとなります。
# モデルの学習・テストを行う抽象クラス
class _AbstractModel(metaclass=ABCMeta):
@abstractmethod
def train_with_tuning(self):
# 学習・チューニング用メソッド
pass
@abstractmethod
def test(self):
# テスト用メソッド
pass
@abstractmethod
def predict(self, data):
# 推論用メソッド
pass
@abstractmethod
def feature_importance(self):
# 特徴量の重要度を計算するためのメソッド
pass具象クラス・具象メソッド
LGBFactory
こちらは、lightGBMを対象としたオブジェクト生成用の具象クラスとなります。
class LGBFactory(_AbstractFactory):
"""
LGBFactory : lightGBM Factory
Attributes
----------
__managers : dict
_LGBManagerのインスタンス一覧
"""
def __init__(self):
"""
初期化
"""
self.__managers = {}
def __update_instance_list(self, instance):
hash_key = id(instance)
if hash_key in self.__managers.keys():
# 保持していた対応関係を削除
del self.__managers[hash_key]
def create(self, df, test_size=0.3, valid_size=0.2, seed=1):
"""
具象クラス生成用のメソッド
Parameters
----------
df : pd.DataFrame
特徴量エンジニアリング後のデータ
test_size : float
テストデータの割合
valid_size : float
検証用データの割合
seed : int
乱数のシード
Returns
-------
instance : _LightGBM
_LightGBMのインスタンス
"""
_train_valid_indices, _test_indices = train_test_split(
df.index.unique(), test_size=test_size, random_state=seed, shuffle=False
)
_train_indices, _valid_indices = train_test_split(
_train_valid_indices, test_size=valid_size, random_state=seed+1, shuffle=False
)
_get_target_data = lambda _df, _indices: _df[_df.index.isin(_indices)]
train_dataset = _get_target_data(df, _train_indices)
validation_dataset = _get_target_data(df, _valid_indices)
test_dataset = _get_target_data(df, _test_indices)
# 訓練用データセット、検証用データセット、テスト用データセットの定義
inputs = {
'train': _LGBManager.create_inputs(train_dataset),
'valid': _LGBManager.create_inputs(validation_dataset),
'test': _LGBManager.create_inputs(test_dataset),
}
# データセット作成
manager = _LGBManager(**inputs)
# 具象クラスのインスタンス作成
instance = _LightGBM(manager, self.__update_instance_list)
# instanceとmanagerを紐づけて管理
self.__managers.update({id(instance): manager})
return instance
def save(self, instance, version='model'):
"""
モデル保存用メソッド
Parameters
----------
instance : _LightGBM
_LightGBMのインスタンス
Returns
-------
relative_filepath : str
出力先のファイルパス
"""
now = datetime.now()
dirname = now.strftime('%Y%m%d')
filename = f'base{version}.pkl'
filepath = os.path.join(SystemPaths.MODEL_DIR, dirname, filename)
hash_key = id(instance)
manager = self.__managers[hash_key]
# 保存
manager.save(manager, filepath)
# 相対パスを返却
relative_filepath = os.path.join(os.path.basename(SystemPaths.MODEL_DIR), dirname, filename)
return relative_filepath
def load(self, filepath):
"""
モデル読み込み用メソッド
Parameters
----------
filepath : str
読み込み先
Returns
-------
instance : _LightGBM
_LightGBMのインスタンス
"""
manager = _LGBManager.load(filepath)
instance = _LightGBM(manager)
# instanceとmanagerを紐づけて管理
self.__managers.update({id(instance): manager})
return instance_lightGBM
こちらは、lightGBMによる学習・推論・評価を行う具象クラスとなります。
class _LightGBM(_AbstractModel):
"""
LightGBM : 決定木をベースとした手法による機械学習手法
Attributes
----------
__manager : _LGBManager
_LGBManagerのインスタンス
"""
def __init__(self, manager, callback=None):
"""
初期化
Parameters
----------
manager : _LGBManager
_LGBManagerのインスタンス
callback : object or None
__del__時に呼び出すコールバック
"""
self.__manager = manager
self.__callback = callback
def __del__(self):
"""
破棄処理
"""
if callable(self.__callback):
self.__callback(self)
def train_with_tuning(self, seed=3, optuna_seed=7):
"""
ハイパーパラメータのチューニングも行いつつ学習する
Parameters
----------
seed : int
チューニング時の乱数のシード
optuna_seed : int
ハイパーパラメータ探索時の乱数のシード
Returns
-------
best_params : pd.DataFrame
データから予測した最適なパラメータ
"""
# 固定するパラメータの設定
params = {
'objective': 'binary', # 目的関数
'metric': 'binary_logloss', # 評価指標
'boosting': 'gbdt', # 勾配ブースティングの種類
'verbose': -1, # ログの出力を抑制
'seed': seed, # 乱数のシード
}
callbacks = [
lgb.early_stopping(stopping_rounds=16, verbose=False),
lgb.log_evaluation(period=0),
]
# ロギングの設定変更
oplog.set_verbosity(oplog.WARNING)
# ハイパーパラメータ探索付きの学習を実施
with warnings.catch_warnings():
# 一時的に警告を無視する
warnings.filterwarnings('ignore')
self.__manager.model = lgb.train(
params, self.__manager.train_dataset,
valid_sets=[self.__manager.train_dataset, self.__manager.validation_dataset],
valid_names=['train', 'valid'],
optuna_seed=optuna_seed,
callbacks=callbacks,
)
best_params = pd.DataFrame({
key: [val]
for key, val in self.__manager.model.params.items()
}).T.set_axis(['best_params'], axis='columns')
return best_params
def test(self):
"""
テスト(評価)
Returns
-------
result : pd.DataFrame
評価結果
"""
# テスト用データを取得
test_dataset = self.__manager.test_dataset.construct()
x_test = test_dataset.get_data()
y_test = test_dataset.get_label()
# 推論
_, y_pred = self.predict(x_test)
# 分類性能を計算
report = classification_report(y_test, y_pred, output_dict=True, target_names=['other', 'Top3'])
# 整形
result = pd.DataFrame(report).T
return result
def predict(self, data):
"""
推論
Parameters
----------
data : numpy.array or pd.DataFrame
入力データ
Returns
-------
probability : np.array
予測確率
prediction : np.array
予測ラベル
"""
probability = self.__manager.model.predict(data, num_iteration=self.__manager.model.best_iteration)
# 最も近い整数に丸める
prediction = np.rint(probability).astype(int)
return probability, prediction
def feature_importance(self):
"""
特徴量の重要度の計算
Returns
-------
result : pd.DataFrame
特徴量の重要度
"""
features = self.__manager.model.feature_name()
importance = self.__manager.model.feature_importance()
result = pd.DataFrame({
'features': features,
'importance': importance
}).sort_values('importance', ascending=False)
return resultデータクラス
_AIManager
こちらは、モデルとデータセットを管理するためのデータクラスとなります。
@dataclass
class _AIManager:
def save(self, target, filepath):
"""
データ保存用メソッド
Parameters
----------
target : object
保存するオブジェクト
filepath : str
保存先
"""
dirname = os.path.dirname(filepath)
# 保存先のディレクトリがない場合
if not os.path.isdir(dirname):
# ディレクトリ作成
os.makedirs(dirname)
with open(filepath, 'wb') as fout:
pickle.dump(target, fout)
@classmethod
def load(cls, filepath):
"""
データ読み込み用メソッド
Parameters
----------
filepath : str
読み込み先
Returns
-------
target : object
保存したデータ
"""
if os.path.exists(filepath):
with open(filepath, 'rb') as fin:
target = pickle.load(fin)
else:
raise Exception(f'Error: {filepath} does not exist.')
return target_LGBManager
こちらは、lightGBM用のデータクラスとなります。
初期化処理を自前で定義したかったため、デコレーターの引数にinit=Falseを追加しています。
このように引数を与えることで、dataclassライブラリが自動生成するメソッドを制御できます。(詳細はコチラを参照)
@dataclass(init=False)
class _LGBManager(_AIManager):
train_dataset: lgb.Dataset
validation_dataset: lgb.Dataset
test_dataset: lgb.Dataset
model: lgb.LightGBMTuner = None
def __init__(self, train, valid, test, model=None):
"""
初期化
Parameters
----------
train : dict
学習用データセット
valid : dict
検証用データセット
test : dict
テスト用データセット
model : lgb.LightGBMTuner or None
モデル
"""
self.train_dataset = lgb.Dataset(**train, free_raw_data=False)
self.validation_dataset = lgb.Dataset(**valid, reference=self.train_dataset, free_raw_data=False)
self.test_dataset = lgb.Dataset(**test, free_raw_data=False)
self.model = model
def save(self, target, filepath):
"""
データ保存用メソッド
Parameters
----------
target : object
保存対象のオブジェクト
filepath : str
保存先
"""
output = {}
# クラス変数のみ抽出
pattern = re.compile('^__')
_func = lambda key: not bool(pattern.match(key)) and hasattr(target, key) and not callable(getattr(target, key))
items = filter(_func, dir(target))
with warnings.catch_warnings():
# 一時的に警告を無視する
warnings.filterwarnings('ignore')
for key in items:
value = getattr(self, key)
if isinstance(value, lgb.Dataset):
# データの取得
dataset = value.set_reference(lgb.Dataset(None)).construct()
_data = dataset.get_data()
_label = dataset.get_label()
_group = dataset.get_group()
value = {'data': _data, 'label': _label, 'group': _group}
output[key] = value
super().save(output, filepath)
@classmethod
def create_inputs(cls, df):
"""
DataFrameから入力データを作成する
Parameters
----------
df : pd.DataFrame
入力データ
Returns
-------
inputs : dict
出力データ
"""
label_name = 'rank'
judge = df[label_name] <= 3
target = df.copy()
target.loc[ judge, label_name] = 1
target.loc[~judge, label_name] = 0
target = target[df[label_name] <= 6]
# データの取得
target.sort_index(inplace=True)
_data = target.drop([label_name], axis=1)
_label = target[label_name]
_group = target.index.value_counts().sort_index()
# 出力データの生成
inputs = {'data': _data, 'label': _label, 'group': _group}
return inputs
@classmethod
def load(cls, filepath):
"""
データを読み込みインスタンスを作成する
Parameters
----------
filepath : str
読み込み先
Returns
-------
instance : _LGBManager
_LGBManagerのインスタンス
"""
target = super().load(filepath)
dummy_data = {'data': None}
inputs = {
'train': target.get('train_dataset', dummy_data),
'valid': target.get('validation_dataset', dummy_data),
'test': target.get('test_dataset', dummy_data),
'model': target.get('model', None),
}
instance = cls(**inputs)
return instance学習部分の解説
lightGBMを用いて学習する際は、いくつか設定が必要になります。
ここでは、必要な設定と学習のさせ方について解説します。
学習時に必要な設定
今回、ハイパーパラメータの探索もあわせて実施しています。
ただ、単純にハイパーパラメータの組み合わせを試していくと非常に時間がかかるため、optunaと呼ばれる、ハイパーパラメータ探索を行うライブラリを利用します。
ライブラリの読み込み
二値分類に限定されますが、optunaには、lightGBM用のハイパーパラメータ探索を行う機能が実装されているため、これをそのまま利用します。
pythonでimportする際は、以下のように1行で完結します。
import optuna.integration.lightgbm as lgb固定するパラメータの設定
lightGBMには、非常に多くのハイパーパラメータがありますが、このうち、必要な部分のみを固定し、それ以外はデフォルト値を使うようにします。
上記の処理は、以下の部分が該当します。
# 固定するパラメータの設定
params = {
'objective': 'binary', # 目的関数
'metric': 'binary_logloss', # 評価指標
'boosting': 'gbdt', # 勾配ブースティングの種類
'verbose': -1, # ログの出力を抑制
'seed': seed, # 乱数のシード
}
callbacks = [
lgb.early_stopping(stopping_rounds=16, verbose=False),
lgb.log_evaluation(period=0),
]基本的な内容はコメントにある通りです。
early_stoppingのみ補足しておくと、early_stoppingは過学習を避けるための処理で、一定回数連続で誤差が更新されなかった場合に学習を打ち切るという処理になります。
今回、打ち切るタイミングは16回としています。
また、再現性を担保するために、機械学習によるモデルを評価する際は、乱数を固定しておくことが重要になります。
このため、学習時の乱数のシードを固定して学習・評価を行うようにしています。
学習
学習自体は非常に簡単で、optunaのlightGBMが用意しているtrainメソッドを利用します。
今回、ロギングやWarningの設定上、直接関係しない処理が含まれていますが、実装結果は以下のようになります。
# ロギングの設定変更
oplog.set_verbosity(oplog.WARNING)
# ハイパーパラメータ探索付きの学習を実施
with warnings.catch_warnings():
# 一時的に警告を無視する
warnings.filterwarnings('ignore')
self.__manager.model = lgb.train(
params, self.__manager.train_dataset,
valid_sets=[self.__manager.train_dataset, self.__manager.validation_dataset],
valid_names=['train', 'valid'],
optuna_seed=optuna_seed,
callbacks=callbacks,
)評価部分の解説
今回は、二値分類のため、推論結果は1着~3着に入る可能性が確率化された状態で得られます。
このため、一番近い整数に丸め込むことで「1着~3着に入る/入らない」を推論結果として得ることができます。
上記の処理は、predictメソッドに実装しています。
def predict(self, data):
"""
推論
Parameters
----------
data : numpy.array or pd.DataFrame
入力データ
Returns
-------
probability : np.array
予測確率
prediction : np.array
予測ラベル
"""
probability = self.__manager.model.predict(data, num_iteration=self.__manager.model.best_iteration)
# 最も近い整数に丸める
prediction = np.rint(probability).astype(int)
return probability, predictionまた、テストデータセットで実際に得られた結果を評価する部分は、testメソッドに実装しています。
def test(self):
"""
テスト(評価)
Returns
-------
result : pd.DataFrame
評価結果
"""
# テスト用データを取得
test_dataset = self.__manager.test_dataset.construct()
x_test = test_dataset.get_data()
y_test = test_dataset.get_label()
# 推論
_, y_pred = self.predict(x_test)
# 分類性能を計算
report = classification_report(y_test, y_pred, output_dict=True, target_names=['other', 'Top3'])
# 整形
result = pd.DataFrame(report).T
return result評価結果
参考までに、評価結果と得られた特徴量の重要度を紹介します。
評価結果
ほぼ勘で当てているのと同じ感じになっていました。

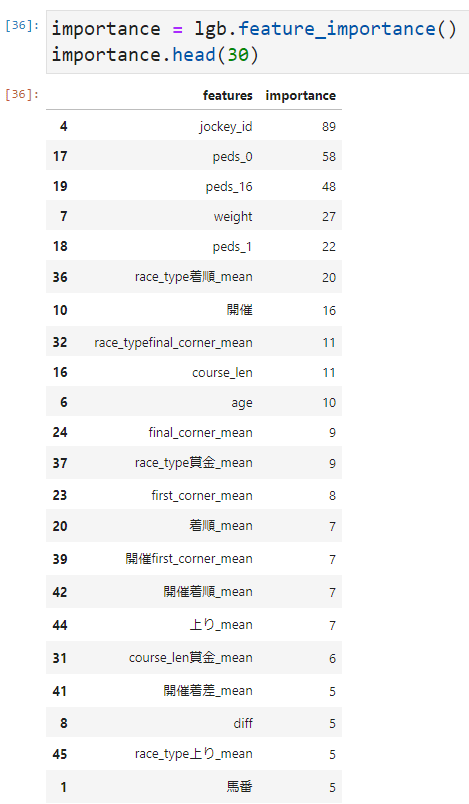
特徴量の重要度
特徴量としては、過去の成績をもとに算出したレース種別ごとの着順や最後の通過時の順位など、有用そうな特徴が利用されていることが分かります。
まとめ
今回は、前処理結果を用いて、lightGBMと呼ばれる機械学習手法で学習・評価する方法について解説しました。
結果としては、実用的な形にはなっていませんが、今回までの活動により、データ収集から学習・評価を一貫して行う環境が準備できたため、後はPDCAサイクルを回せる状態になったと考えています。
改善箇所が検討できたタイミングで、再度、記事にまとめたいと思います。
効率良く技術習得したい方へ
今回の話の中で、プログラミングについてよく分からなかった方もいると思います。
このような場合、エラーが発生した際に対応できなくなってしまうため、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。