

joblibを使ってバッチ処理により並列化を行っている。
ただ、バッチ単位の進捗状況が分からないため、改善方法を教えて欲しい。
こんなお悩みを解決します。
pythonで時間がかかる処理を実行する場合、joblibを使うことで所要時間を短縮することができます。
一方、プロセス生成やデータ通信によるオーバーヘッドが発生するため、なるべくバッチの数を少なくして効率良く処理することが重要になります。
ただ、この方法の場合、バッチ1つあたりの処理時間が長くなるため、進捗状況を確認するのが困難になります。
そこで、今回は、バッチレベルで進捗状況を確認する方法について解説します。
効率良く技術習得したい方へ
短期間でプログラミング技術を習得したい場合は、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。
-

-
【比較】プログラミングスクールおすすめランキング6選【初心者向け】
続きを見る
複数のCPUによる並列処理
まず、複数のCPUを用いた並列処理の概要について解説します。
処理時間を削減する際は、独立して処理できるタスクをバッチという単位で分割し、分割したバッチを複数のCPUに割り当て同時に実行する、という方法が挙げられます。
この方法は「並列処理」と呼ばれ、処理のイメージは、以下のようになります。
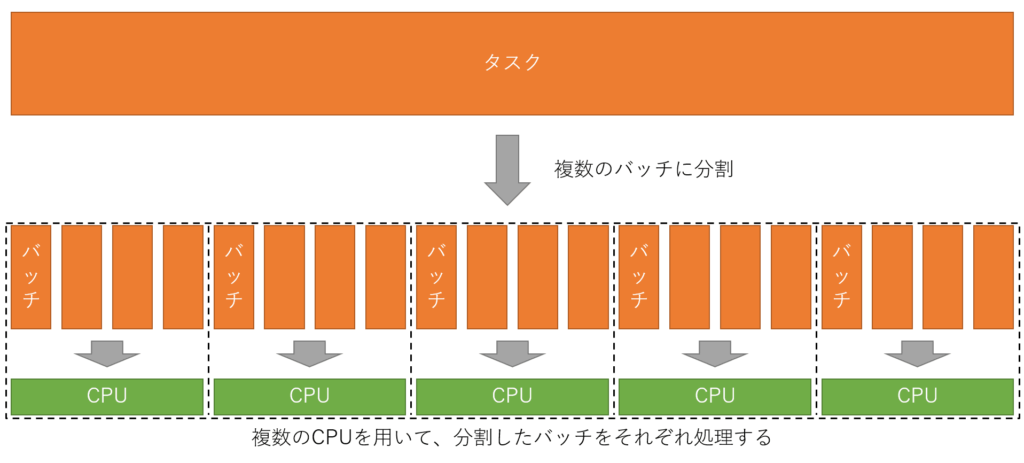
上記の図では、分かりやすさを優先した構成となっていますが、実際は処理が終わったCPUが残りのバッチを処理する、という対応になります。
joblibは、上記の並列処理を手軽に実現するためのライブラリの一つです。
【従来法】バッチ単位での進捗情報の確認方法
並列処理が必要となる場合、30分や1時間経っても計算が終わらないという状況が発生します。
このような場合、処理の進捗状況を確認できることが望ましいです。
バッチ単位で処理の進捗状況を確認する方法は、Stack Overflowでも取り上げられており、以下のような実装により実現できます。
import contextlib
import joblib
import math
from tqdm.auto import tqdm
# joblibで用いるtqdm用の関数を定義
@contextlib.contextmanager
def tqdm_joblib(total, **kwargs):
progress_bar = tqdm(total=total, smoothing=0, **kwargs)
class TqdmBatchCompletionCallBack(joblib.parallel.BatchCompletionCallBack):
def __call__(self, *args, **kwargs):
progress_bar.update(n=self.batch_size)
return super().__call__(*args, **kwargs)
old_batch_callback = joblib.parallel.BatchCompletionCallBack
joblib.parallel.BatchCompletionCallBack = TqdmBatchCompletionCallBack
try:
yield progress_bar
finally:
joblib.parallel.BatchCompletionCallBack = old_batch_callback
progress_bar.close()
# ========
# 利用方法
# ========
with tqdm_joblib(total=100):
joblib.Parallel(n_jobs=5)([joblib.delayed(math.sqrt)(float(i)) for i in range(100)])tqdm_joblib関数は、コチラの実装を参考にしました。
従来法の問題点
上記の方法で進捗状況は確認できますが、実際に使用する上では、以下の3つの問題が残ります。
- 各CPUに割り当てた進捗状況が確認できない。
- バッチ単位で進捗状況を確認することになるため、バッチ単位の処理に時間がかかる場合、更新結果がなかなか得られない。
- 進捗状況を知るために細かくバッチを分けると、プロセス生成やデータ通信によるオーバーヘッドが生じ、バッチ単体の処理時間が増大する。
それぞれ、個別に解説します。
各CPUに割り当てた進捗状況の確認が困難である
これは、実際の出力結果を確認いただくと分かると思います。
上記のプログラムを用いて、以下のような並列処理を実行した場合を想定します。
# ===========
# = Sample1 =
# ===========
# 並列化対象の関数
def _user_func(x):
time.sleep(2.0)
return x
# main関数
def main():
with tqdm_joblib(total=100):
result = joblib.Parallel(n_jobs=4)([
joblib.delayed(_user_func)(i) for i in range(100)
])
return resultこの実行結果の進捗状況は、以下のように表示されます。

このように、4つのCPUを用いて並列処理していますが、1つの進捗状況として管理されており、それぞれの負荷状況が確認できない状態となっています。
バッチ単位の処理時間により進捗状況の更新頻度が変化する
効率化を見据えて、以下のようにバッチの数を減らした場合を想定します。
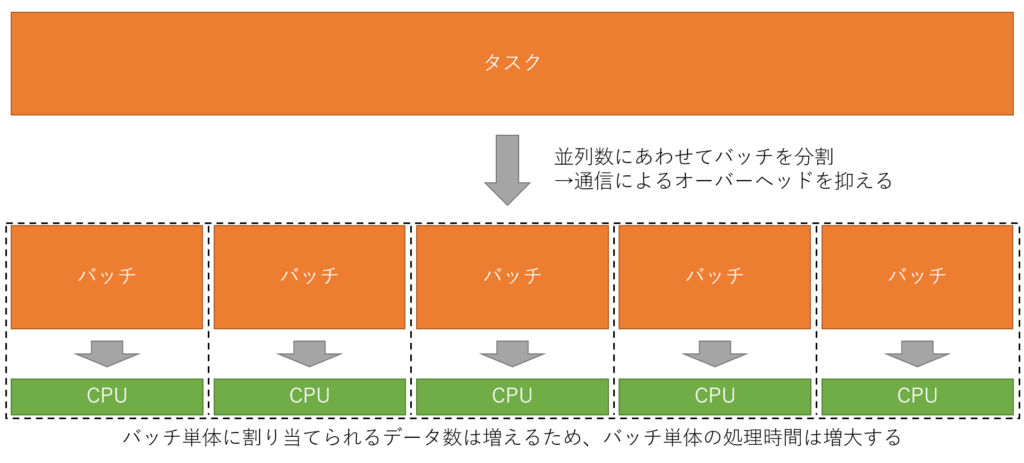
この時のプログラムは以下のようになります。
ただし、バッチ単位でのタスク数は増大するため、下記の例ではfor loopを用いて、疑似的にタスク数を調整しています。
# ===========
# = Sample2 =
# ===========
# 並列化対象の関数
def _user_func(x):
# 疑似的に割り当てられたタスク数を25倍(= 100/4)にする
for i in range(25):
time.sleep(2.0)
return x
# main関数
def main():
with tqdm_joblib(total=4):
# データ数を4つに減らして、各CPUに1つのバッチが与えられるように変更する
result = joblib.Parallel(n_jobs=4, pre_dispatch='n_jobs')([
joblib.delayed(_user_func)(i) for i in range(4)
])
return result実行結果は以下のようになり、バッチ単位の処理が終了するタイミング(2秒/回×25回=50秒)で、一斉に進捗状況が更新されていることが分かります。

このように、現状では、バッチ単位の処理に時間がかかる場合、プログレスバーの更新タイミングも処理時間に依存します。
プロセス生成やデータ通信によりオーバーヘッドが生じる
並列処理を行う際は、実際の処理時間に加え、プロセス生成やデータ通信にかかる時間も考慮する必要があります。
以下に示すように、タスクを分割しすぎるとその分データ通信の頻度も増大するため、並列処理の恩恵を受けにくくなります。
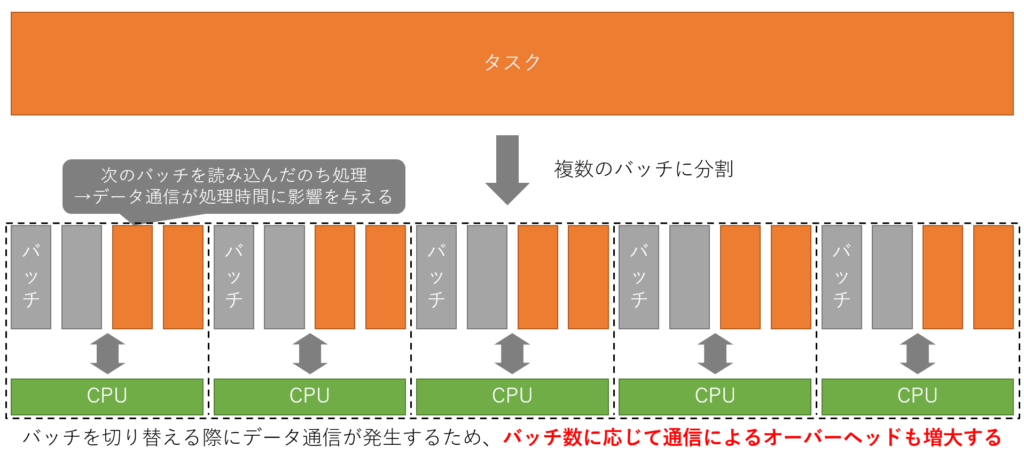
【改善方法】ThreadとQueueを用いた進捗状況の管理
これまでに示した問題点をまとめると、バッチ単位の進捗状況しか分からないことが要因であることが分かります。
このため、バッチレベルの進捗状況が分かるようになれば、問題は解決できます。
コードレベルで説明すると、以下のコメント部分の進捗状況が確認できれば良いことになります。
def _user_func(x):
for i in range(25):
# ==========================
# この部分の処理において、
# 進捗状況が確認できればよい
# ==========================
time.sleep(2.0)
return x
def main():
with tqdm_joblib(total=4):
result = joblib.Parallel(n_jobs=4, pre_dispatch='n_jobs')([
joblib.delayed(_user_func)(i) for i in range(4)
])
return result今回は、threading.Threadとmultiprocessing.Manager.Queueを用いて、バッチレベルの進捗状況を更新する仕組みを構築します。
仕組みの概要
仕組み自体は以下に示す通りで、Queueを経由してサブプロセスごとの進捗状況をメインプロセス側で管理する方式となります。
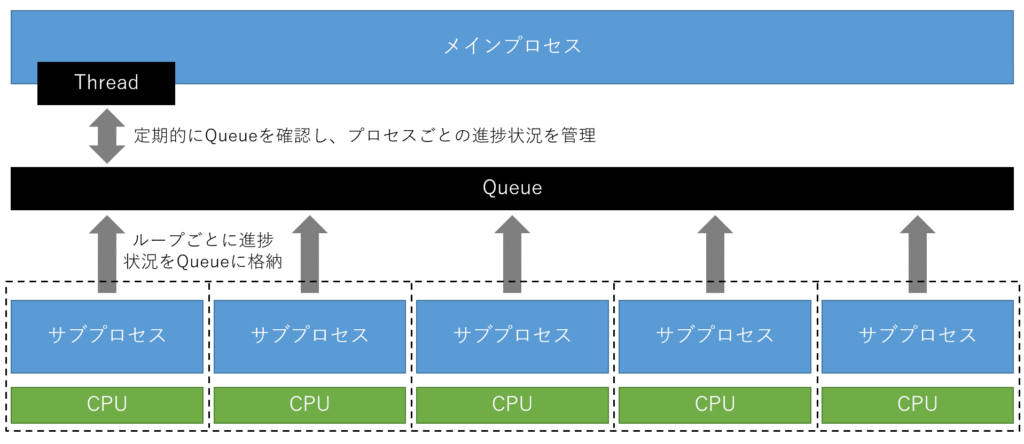
実装結果&使用方法の例
今回は、上記の仕組みをTqdmJoblibProcessとして実装しました。※一部利用時の制約があります。
実装方法はいくつかやり方があると思いますが、下記に一例を示しておきたいと思います。
import os
import joblib
import numpy as np
import time
from multiprocessing import Manager
from threading import Thread
from tqdm.auto import tqdm
from dataclasses import dataclass
@dataclass
class _Status:
is_running: bool
pid: int
value: int
class TqdmJoblibProcess:
def __init__(self, n_jobs):
# 使用できるCPU数を取得
n_cpus = int(os.cpu_count())
if n_jobs == 0:
# ジョブ数に指定がない場合、すべてのCPUを利用する
n_workers = n_cpus
else:
# joblibでは、n_jobs=-1といった指定も可能なため、
# 上記の指定に合わせてn_workersを計算する
n_workers = n_cpus + 1 + n_jobs if n_jobs < 0 else n_jobs
self.n_workers = n_workers
def __monitor_progress(self, totals, queue):
# workerの数に応じてプログレスバーを用意
progress_bars = [
tqdm(desc=f'Worker {pid + 1}', total=total, position=pid, smoothing=0)
for pid, total in enumerate(totals)
]
is_running = True
while is_running:
try:
# statusを取得し、該当するプログレスバーの内容を更新
status = queue.get()
is_running = status.is_running
progress_bars[status.pid].update(status.value)
except:
pass
# 後処理
for pbar in progress_bars:
pbar.close()
def execute(self, targets, function, *args, **kwargs):
def _wrapper(pid, queue, batch, function, *args, **kwargs):
# ループごとに呼ばれる関数を定義
callback = lambda: queue.put(_Status(is_running=True, pid=pid, value=1))
return function(batch, callback, *args, **kwargs)
# ============
# main routine
# ============
arr = np.array(targets)
mod = np.mod(arr.size, self.n_workers)
# 各CPUに1つのバッチが割り当てられるようにデータ数を調整
if mod > 0:
# padding
pad_size = self.n_workers - mod
padding = np.pad(arr, pad_width=[(0, pad_size)], mode='constant', constant_values=arr[-1])
# 末端のデータを調整しつつバッチに分割
sliced = padding.reshape(self.n_workers, -1)
batches = sliced[:-1, :].tolist() + [sliced[-1, :-pad_size].tolist()]
else:
batches = arr.reshape(self.n_workers, -1).tolist()
# 各バッチのデータ数を定義
totals = [len(batch) for batch in batches]
with Manager() as manager:
queue = manager.Queue()
try:
# 進捗状況を監視するthreadを生成
progress_thread = Thread(target=self.__monitor_progress, args=(totals, queue))
progress_thread.start()
# joblibによる並列処理
results = joblib.Parallel(n_jobs=self.n_workers, pre_dispatch='n_jobs')([
joblib.delayed(_wrapper)(pid, queue, batch, function, *args, **kwargs)
for pid, batch in enumerate(batches)
])
except Exception as err:
raise Exception(err)
finally:
# すべてのタスクが完了したことをthreadに通知
queue.put(_Status(is_running=False, pid=0, value=0))
progress_thread.join()
return results使用方法の例は、以下のようになります。
# 並列化対象の関数
def _user_func(batch, callback):
# 制約:関数の第1引数、第2引数として以下を指定
# 第1引数: batch処理に用いるデータ
# 第2引数: callback関数
for i in batch:
time.sleep(2.0)
# ループの末端でcallback関数を呼び出す
callback()
return batch
# インスタンス生成
tjp = TqdmJoblibProcess(4)
# 並列処理を実行
result = tjp.execute(range(100), _user_func)
# 出力(略記): [range(0,25), range(25,50), range(50,75), range(75,100)]TqdmJoblibProcessの制約
使い方の例に示したように、並列化対象の関数を定義する際は、以下の制約を満たす必要があります。
| 関数定義時の制約 | 内容 |
|---|---|
| 第1引数に関する制約 | バッチ処理時に受け取るデータを指定する。 |
| 第2引数に関する制約 | callback関数を指定する。 |
| コードに関する制約 | for loop終了直前でcallback関数を呼び出す。 |
ユーザが指定した任意のパラメータを利用したい場合
TqdmJoblibProcessでは、execute関数に可変長引数(*args)と可変長キーワード引数(**kwargs)を受け付けるようにしています。
これらを用いることで、ユーザが指定した任意のパラメータを並列化対象の関数に与えることができます。
実際の使用例を以下に示します。
def _user_func_with_params(batch, callback, args1, kwargs1=3):
x = args1 + kwargs1
for i in batch:
time.sleep(2.0)
callback()
return x
tjp = TqdmJoblibProcess(4)
# args1を2、kwargs1を5として関数を呼び出す
result = tjp.execute(range(100), _user_func_with_params, 2, kwargs1=5)
# 出力: [7, 7, 7, 7]実行結果
実行結果は以下のようになり、期待通りバッチレベルでの進捗状況を確認することができました。

まとめ
今回は、joblibを用いた並列処理を行う場合において、バッチレベルで進捗状況を確認する方法について解説しました。
メモリに搭載しきれない程のデータを扱っている方はオーバーヘッドが生じることを許容するしかないかもしれませんが、メモリに搭載できる範囲で大規模なデータを扱っている方は、バッチの数を調整し、オーバーヘッドを抑えることで高速化が期待できます。
また、pythonには、GIL (Global Interpreter Lock) と呼ばれる排他ロックの仕組みがあり、複数スレッド下でもロックを持つ単一スレッドでしか処理が実行できない、という特有の問題があります。
このため、スレッドによる高速化は頭打ちとなってしまうため、今回のようにマルチプロセスによる高速化に頼ることとなります。
並列処理には、上記のような背景がありますが、使う側としては結果だけ知っていれば良いので、興味がある方は今回の実装例を参考にしてみてください。
効率良く技術習得したい方へ
今回の話の中で、プログラミングについてよく分からなかった方もいると思います。
このような場合、エラーが発生した際に対応できなくなってしまうため、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。
-
-
【比較】プログラミングスクールおすすめランキング6選【初心者向け】
続きを見る